4月8日至9日,由中国人工智能学会主办的人工智能大模型技术高峰论坛将在杭州萧山举办。会议议程显示,华为云人工智能领域首席科学家田奇将介绍“盘古大模型的进展及其应用”。
华为自2020年开始布局大模型,盘古大模型是由CV(计算机视觉)大模型、科学计算大模型、NLP(自然语言处理)大模型、语音大模型、多模态大模型组成的系列,于2021年4月正式发布,彼时华为便表示盘古NLP大模型是业界首个千亿级生成与理解中文的NLP大模型。
根据华为云官网显示,华为即将上线的“盘古系列AI大模型”分别为NLP大模型、CV大模型、科学计算大模型,都已经被标注为即将上线状态。
 据华为介绍,其中NLP大模型在预训练阶段学习了40TB中文文本数据,被认为在最接近人类中文理解能力的AI大模型;CV大模型是业界最大CV大模型、首次实现兼顾图像判别与生成能力、首次实现了模型的按需抽取、在ImageNet上小样本学习能力上的业界第一;科学计算大模型应用于应用于气象、生物医药等领域。
据华为介绍,其中NLP大模型在预训练阶段学习了40TB中文文本数据,被认为在最接近人类中文理解能力的AI大模型;CV大模型是业界最大CV大模型、首次实现兼顾图像判别与生成能力、首次实现了模型的按需抽取、在ImageNet上小样本学习能力上的业界第一;科学计算大模型应用于应用于气象、生物医药等领域。
▌基于工业化AI开发模式 侧重B端场景
从技术上看,盘古大模型基于“预训练+下游微调”的工业化AI开发模式,拥有泛化能力强、小样本学习和模型高精度三大特性,一个模型就可适用大量复杂的行业场景,即使少量样本也能达到高精度。
基于此,华为大模型产业化的初衷在于开辟更多B端业务场景,正如田奇此前所说,“将工业化的一面放置在更高的优先级上”。
中信建投研报指出,目前盘古预训练大模型能力已经在包括能源、零售、金融、工业等领域得到验证。同时盘古NLP大模型通过迁移学习实现少样本学习的目标,将P-tuning等最新技术融入到盘古的微调框架中,并通过庞大的行业知识库进行训练,使其更适合在复杂商用场景下的应用能力强于GPT-3。
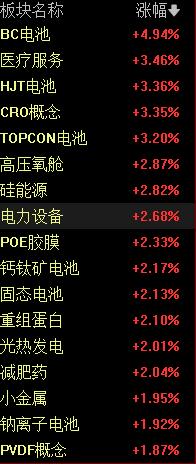
从具体场景来看,例如,在电力领域,华为大模型可以替代厂商原先的20多个小模型,极大减少了模型维护成本,平均精度提升18.4%,模型开发成本降低90%。
在实时海浪预测项目,传统科学计算模型在预测海浪高度变化的时候,需要消耗海量的超算算力。但基于盘古科学计算大模型,可在保证准确率的前提下,将预测速度提升到了原来的10000倍。
盘古药物分子大模型的成药性预测准确率比传统方式高20%,进而提升研发效率,让先导药的研发周期从数年缩短至一个月,同时降低70%的研发成本。
▌“安卓时代”正拉开帷幕 盘古有何优势?
OpenAI率先推出的GPT大模型开启了通用AI的新时代,此举被誉为AI的“iPhone时刻”,而正如iPhone推出后并没有独霸手机市场,其他派系的手机层出不穷,此后的几十年里iOS、安卓系更是竞相迭代,创造了一个移动互联网盛世。
如今,OpenAI之外,国内外许多企业都在紧锣密鼓研发AI模型,国外代表企业有谷歌、Meta,国内包括华为、百度、阿里、腾讯、商汤、三六零、科大讯飞、拓尔思、昆仑万维、云从科技等,继“iPhone时刻”之后,“安卓时代”正拉开帷幕。
与其他大模型相比,华为的优势或在于拥有完整的产业链和较强的算力调配能力。以“AI底座”算力为例,华为握有鲲鹏和昇腾两张牌。据介绍,在训练千亿参数的盘古大模型时,华为团队调用了超过2000块的昇腾910,进行了超过2个月的训练。
鲲鹏:华为自主芯片→鲲鹏芯片→鲲鹏服务器→欧拉操作系统→高斯数据库→行业应用向外扩张,构建鲲鹏生态,提供算力支撑。
昇腾:昇腾AI处理器→CANN异构计算架构→MindSporeAI框架→应用使能→行业应用,助力打造华为昇腾全栈AI软硬件平台,构筑智能世界基石。
 天风证券认为,盘古NLP大模型可以实现一个AI大模型在众多场景通用、泛化和规模化复制,减少对数据标注的依赖,让AI开发由作坊式转变为工业化开发的新模式。其分析师缪欣君预计,未来随着盘古系列AI大模型的上线,将持续赋能金融、电力、交通、气象、物流等行业,华为产业链及下游应用相关公司有望持续受益。
天风证券认为,盘古NLP大模型可以实现一个AI大模型在众多场景通用、泛化和规模化复制,减少对数据标注的依赖,让AI开发由作坊式转变为工业化开发的新模式。其分析师缪欣君预计,未来随着盘古系列AI大模型的上线,将持续赋能金融、电力、交通、气象、物流等行业,华为产业链及下游应用相关公司有望持续受益。
东吴证券王紫敬等人在3月27日发布的研报中表示,华为盘古大模型的优势在于人才储备和算力自主可控,有望成为国内领先的大模型,其生态产业链标的有望迎来加速发展。
文章来源:财联社

未经允许不得转载:财富在线科技 » 大模型“安卓时代”开启!华为盘古新版本即将亮相,B端应用能力或超GPT-3